> ## Documentation Index
> Fetch the complete documentation index at: https://s2.dev/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Architecture
> S2's cellular cloud architecture delivers elastic scale, durable writes, and low-latency reads without operational overhead.
s2.dev is organized into [cells](/platform/cells): isolated deployments located in a specific cloud region.
You don't need to know any of this to use the service.
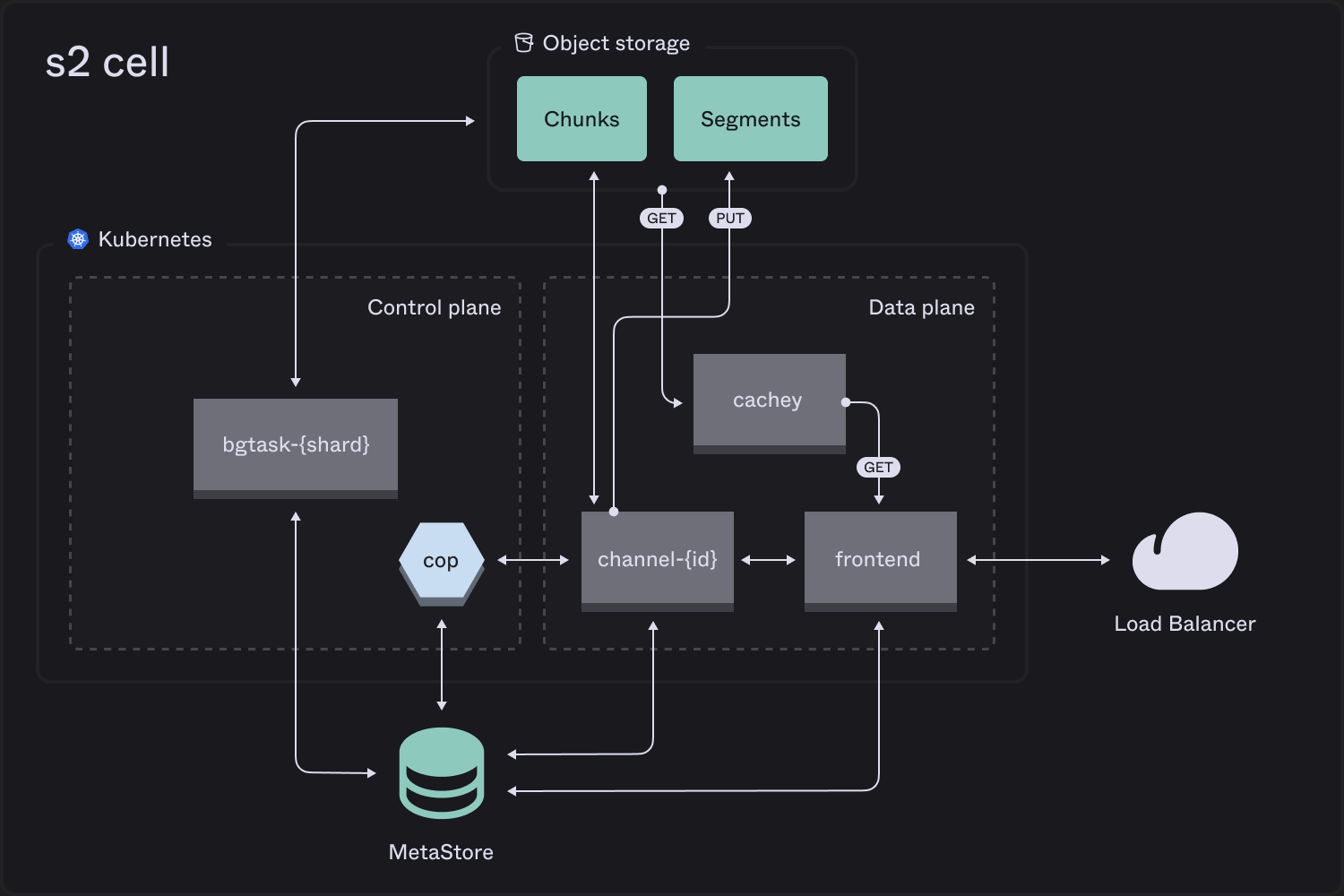 * `cop` ("channel operator") ensures resilience and elasticity of stateful pieces:
* supervises and creates/destroys channels
* rebalances load by migrating streams
* `bgtask` ("background task") workers partitioned on role and keyspace handle async jobs, such as garbage collection.
* `frontend` replicas are an elastic deployment that fronts all API requests, acting as a gateway layer.
* `cachey` replicas form an elastic read-through cache per zone for all reads from object storage.
* `channel` pods sequence writes with a WAL maintained as sequential *chunks*, and flush batched stream *segments* accumulated over a longer timeframe.
Our read-through cache, [cachey](https://github.com/s2-streamstore/cachey), is an open source project.
## Write path
The `frontend` talks to the assigned `channel` for the stream to append records.
If necessary it will first activate the stream by assigning to a `channel` using [power of 2 choices](https://www.eecs.harvard.edu/~michaelm/postscripts/handbook2001.pdf) for load balancing.
Channels multiplex stream records in chunks on object storage (effectively a [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)), flushing based on a combination of elapsed time and accumulated size. Appends are only acknowledged when associated records are durable in a chunk.
Over a longer timeframe, channels batch records from the WAL into per-stream segments and update stream metadata to reference them. This keeps the write acknowledgement path short while giving the read path larger, stream-local object byte ranges to scan.
Once a stream is active, metadata storage is not in the hot-path of writes — only object storage.
## Read path
The `frontend` uses stream metadata to generate a concatenated iteration over relevant stream segments. This is further chained with pointers into chunks (the channel WAL), if the client is reading recently-written data.
It fetches relevant object byte ranges via a `cachey` pod in its own zone, using rendezvous hashing with bounded load to optimize hit rate without hotspotting.
Concurrent reads are combined wherever possible:
* Tailing readers are coalesced on the `frontend` as well as `channel`
* `cachey` will coalesce reads for the same "page" of an object
s2.dev effectively implements a purpose-built CDN for streaming data.
## Stream lifecycle
Streams are made up of a chain of *streamlets*. There is usually only one, but multiple may exist when the stream is being migrated between channels, or migration(s) recently completed.
Streamlets take up a tiny amount of memory on channels — and only stick around if there have been recent writes.
Dormant streams live only as metadata and segment data.
## Storage classes
The choice of storage class affects latency of appending and reading recently-written records.
In AWS,
* `Standard` is powered by channels operating against an S3 Standard chunk storage bucket, which guarantees writes are durable in multiple zones.
* `Express` is powered by channels operating against a quorum of *three* S3 Express zonal chunk storage buckets – so writes are still guaranteed to be durable in multiple zones, but with much lower latency.
## Quality of service
Admission control and load balancing logic is embedded into components in the online request path. Auto-scaling and stream migrations handle sustained shifts.
To optimize throughput, the data plane employs pipelining, i.e. multiple in-flight operations with an ordering dependency. This is not just a server-side concern, S2 client SDKs will also pipeline when using the append and read [session](/api/protocol#sessions) APIs.
Stream migrations use a speculation-based protocol that keeps the write pipeline flowing to minimize disruption.
## Correctness
Beyond unit and integration tests, we practice [deterministic simulation testing](https://s2.dev/blog/dst). S2 involves many moving parts, and investing in DST allows us to test the invariants the system must always uphold.
Deterministic testing lets us run the processes that comprise S2 over a simulated network. We can inject faults, crash processes randomly, trigger recovery procedures, and check that we do not violate our commitments to durability and strong consistency.
Our setup includes a custom Rust framework built with [Turmoil](https://github.com/tokio-rs/turmoil), which we run in CI/CD and in larger nightly searches for subtle regressions. We also use [Antithesis](https://antithesis.com/) as a second form of DST, and verify linearizability with the [Porcupine model checker](https://s2.dev/blog/linearizability).
## Local
The open source implementation of S2 has a distinct architecture optimized for ease of deployment as a single binary. See how it [compares with the cloud service](/s2-lite#cloud-service-comparison).
* `cop` ("channel operator") ensures resilience and elasticity of stateful pieces:
* supervises and creates/destroys channels
* rebalances load by migrating streams
* `bgtask` ("background task") workers partitioned on role and keyspace handle async jobs, such as garbage collection.
* `frontend` replicas are an elastic deployment that fronts all API requests, acting as a gateway layer.
* `cachey` replicas form an elastic read-through cache per zone for all reads from object storage.
* `channel` pods sequence writes with a WAL maintained as sequential *chunks*, and flush batched stream *segments* accumulated over a longer timeframe.
Our read-through cache, [cachey](https://github.com/s2-streamstore/cachey), is an open source project.
## Write path
The `frontend` talks to the assigned `channel` for the stream to append records.
If necessary it will first activate the stream by assigning to a `channel` using [power of 2 choices](https://www.eecs.harvard.edu/~michaelm/postscripts/handbook2001.pdf) for load balancing.
Channels multiplex stream records in chunks on object storage (effectively a [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)), flushing based on a combination of elapsed time and accumulated size. Appends are only acknowledged when associated records are durable in a chunk.
Over a longer timeframe, channels batch records from the WAL into per-stream segments and update stream metadata to reference them. This keeps the write acknowledgement path short while giving the read path larger, stream-local object byte ranges to scan.
Once a stream is active, metadata storage is not in the hot-path of writes — only object storage.
## Read path
The `frontend` uses stream metadata to generate a concatenated iteration over relevant stream segments. This is further chained with pointers into chunks (the channel WAL), if the client is reading recently-written data.
It fetches relevant object byte ranges via a `cachey` pod in its own zone, using rendezvous hashing with bounded load to optimize hit rate without hotspotting.
Concurrent reads are combined wherever possible:
* Tailing readers are coalesced on the `frontend` as well as `channel`
* `cachey` will coalesce reads for the same "page" of an object
s2.dev effectively implements a purpose-built CDN for streaming data.
## Stream lifecycle
Streams are made up of a chain of *streamlets*. There is usually only one, but multiple may exist when the stream is being migrated between channels, or migration(s) recently completed.
Streamlets take up a tiny amount of memory on channels — and only stick around if there have been recent writes.
Dormant streams live only as metadata and segment data.
## Storage classes
The choice of storage class affects latency of appending and reading recently-written records.
In AWS,
* `Standard` is powered by channels operating against an S3 Standard chunk storage bucket, which guarantees writes are durable in multiple zones.
* `Express` is powered by channels operating against a quorum of *three* S3 Express zonal chunk storage buckets – so writes are still guaranteed to be durable in multiple zones, but with much lower latency.
## Quality of service
Admission control and load balancing logic is embedded into components in the online request path. Auto-scaling and stream migrations handle sustained shifts.
To optimize throughput, the data plane employs pipelining, i.e. multiple in-flight operations with an ordering dependency. This is not just a server-side concern, S2 client SDKs will also pipeline when using the append and read [session](/api/protocol#sessions) APIs.
Stream migrations use a speculation-based protocol that keeps the write pipeline flowing to minimize disruption.
## Correctness
Beyond unit and integration tests, we practice [deterministic simulation testing](https://s2.dev/blog/dst). S2 involves many moving parts, and investing in DST allows us to test the invariants the system must always uphold.
Deterministic testing lets us run the processes that comprise S2 over a simulated network. We can inject faults, crash processes randomly, trigger recovery procedures, and check that we do not violate our commitments to durability and strong consistency.
Our setup includes a custom Rust framework built with [Turmoil](https://github.com/tokio-rs/turmoil), which we run in CI/CD and in larger nightly searches for subtle regressions. We also use [Antithesis](https://antithesis.com/) as a second form of DST, and verify linearizability with the [Porcupine model checker](https://s2.dev/blog/linearizability).
## Local
The open source implementation of S2 has a distinct architecture optimized for ease of deployment as a single binary. See how it [compares with the cloud service](/s2-lite#cloud-service-comparison).