S2 delivers streams as a cloud storage primitive, which means no limit on the number of streams you can create and access, with a simple, serverless API and pricing model.
The dominant pattern in durable streaming today is to use sharded topics as a "firehose". This works fine for transporting, say, clickstream data into a data lake. But it is the wrong fidelity for a rising class of applications: agents.
Unlike a synchronous and stateless request-response cycle, sessions are often deeply stateful and long-running. For example, consider AI agents handling travel booking, customer support, or legal assistance; balancing learned preferences over multi-turn conversations.
Each session charts a distinct path with its own context, decisions, and outcomes. It sure quacks like a stream!
Landscape
Traditional streaming will have you choose between:
- Small number of durable topics (Kafka1, Kinesis2) — multiplexing unrelated sessions through shared pipes
- Expensive ephemeral state (Redis3, NATS4) — sacrificing durability for granularity
You might then turn towards a more general database with a row-per-event model. For a streaming workload, OLTP databases (like Postgres) imply high costs 5, while OLAP databases (like ClickHouse) come with very high write latencies 6. Neither will let you tail a fine-grained event stream.
Most databases are designed for where you landed up — streams are the journey. And with agents, the specific journeys matter.
Why agents need granular streams
Memory
Write-ahead logs (WALs) are a fundamental technique for databases, and have a parallel in the practice of event sourcing for applications. It applies perfectly to building agents you can rely on.
The high-level idea is to use what is in effect an "agent WAL". All activity is modelled as events on a session-specific durable stream — so this includes user inputs, prompts, model responses, and tool calls.
This gives us a solid foundation for agent memory. A sketch:
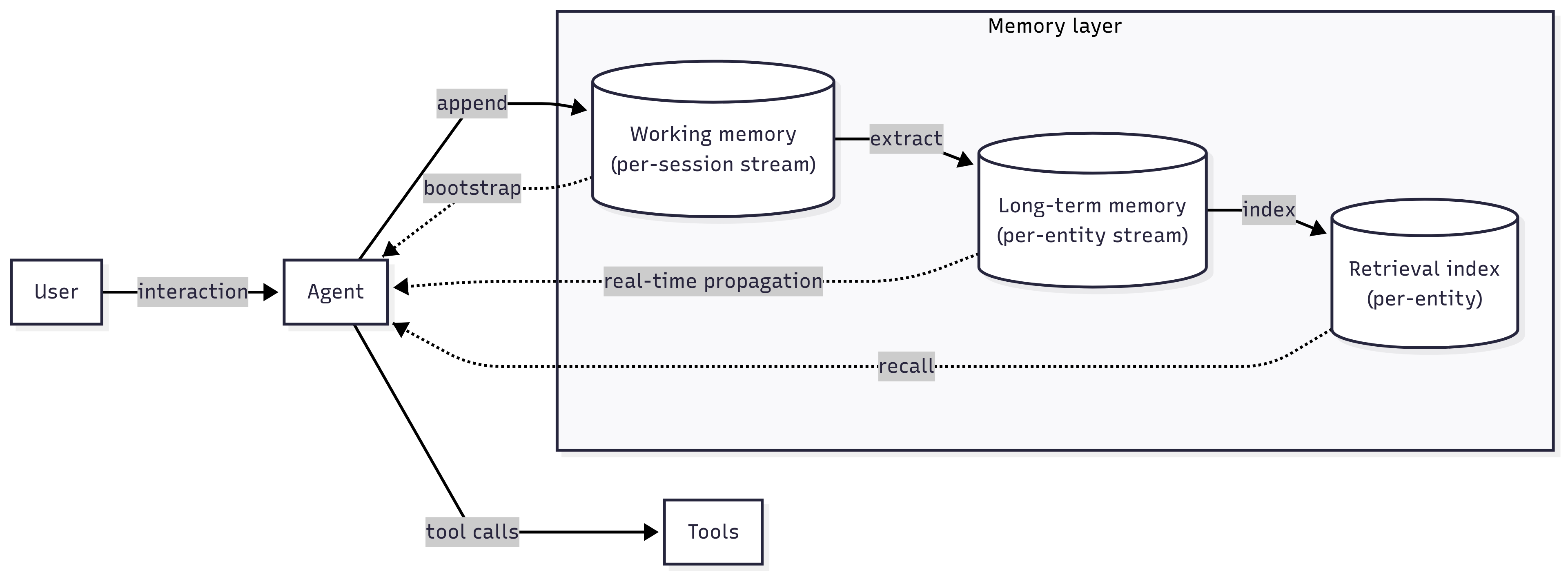
Working memory
The session-specific stream serves as a replayable source of working memory for an agent. When an agent experiences any kind of interruption and needs to be reincarnated, the context can be completely restored quickly.
However, the perspective of working memory as merely being context for an AI model is narrow. A unified treatment includes resilience to crashes, i.e. can the agent truly remember and resume where it left things off? What if the latest we know, based on the stream, is that the agent noted its intent to call an API, but the result was not recorded?
The service being invoked must cooperate to facilitate idempotent retries, usually by allowing the client to provide a unique token. Then this idempotence token can be stored alongside the intent, and voilà, it is safe to retry and resolve the result.
If you have come across durable execution frameworks/runtimes, this is essentially what is going on, with varying degrees of intrusiveness. None will magically make a third-party API idempotent, and it is important to peek under the layers of abstraction to question if they are helping or obscuring.
Long-term memory
The working memory stream can be used to identify insights worth preserving. This may happen inline by instructing the primary model, or by replaying the stream into another model.
As long-term memories are extracted, they can be made available across sessions by writing them to an entity-level (per user, per project, etc.) stream. This naturally preserves the order in which those memories were made, which is meaningful as facts may be overridden.
While context window sizes continue to grow, they are not infinite, and model performance starts to degrade. A stream as a source of truth for long-term memories enables us to asynchronously and reliably build specialized indexes — lexical, vector, graph, or a combination — for efficient memory retrieval7 without loading the entire history.
Moreover, memories may be consolidated and reindexed as they grow in size, by using a versioning approach to stream and index resources. The previous versions serve as raw input for this compaction process — yet another time-tested pattern in data systems 8, that is being referred to as recursive summarization in this, er, context.
Auditability
Immutability is a cornerstone of AI applications that can be trusted with real-world consequences.
With agency in the mix, you need to be able to audit exactly what context went into going down a certain path. Why the $450 United flight was rejected for the $520 Delta option, how the user's "I need to arrive before 3pm" constraint eliminated 60% of options.
Streams are append-only, and the history is immutable by design. This unlocks a whole lot:
- trace a session for debugging
- detect patterns of abuse or manipulation, such as prompt injection attacks
- transparently share with your users how decisions affecting them were made
- comply with laws and regulations, such as non-discrimination
- construct evaluation datasets based on actual interactions
Isolation
Building secure multi-tenant agentic applications requires strict boundaries. We don't want context from one session bleeding into another due to accident or abuse — only by design, such as long-term memory for the same user.
Isolation is natural with granular streams. If you use S2, you can even enforce fine-grained access control.
Branching
When an agent reaches a critical decision point, you can:
- Clone9 the stream at that point
- Explore alternative paths in parallel
- Compare outcomes
- Merge the most promising path back into the main timeline
This enables sophisticated planning and "what-if" analysis without corrupting the primary flow. git checkout for agents!
In how we built our multi-agent research system, Anthropic note:
Asynchronous execution would enable additional parallelism: agents working concurrently and creating new subagents when needed. But this asynchronicity adds challenges in result coordination, state consistency, and error propagation across the subagents. As models can handle longer and more complex research tasks, we expect the performance gains will justify the complexity.
Granular, durable streams are a simplifying primitive to tackle these challenges.
Patterns over frameworks
We don't have a framework to sell you on. You can be as minimalist with these ideas as your application demands.
Event sourcing as a pattern has been around forever. It matches how state actually evolves: as a sequence of events over time. Agent sessions are no different, and AI models provide inference APIs expecting exactly this framing.
But here's what's different now: the infrastructure finally matches the pattern. You can create a durable stream for every session, every user journey, every parallel exploration — without worrying about extreme costs or operational complexity.
If you are excited to count on streams as a primitive, we would love to help! You can join our Discord, email us, or jump straight into the quickstart.
Footnotes
-
Kafka protocol and implementations are not designed from the lens of large numbers of lightweight streams; partitions are treated as provisioned resources. ↩
-
Kinesis on-demand costs $29 per month per stream, so like Kafka it treats them as a resource to be provisioned. ↩
-
AWS MemoryDB may be the only Redis implementation whose durability can be relied on, but also requires expensive provisioned nodes bundling compute and storage. ↩
-
Core NATS is not durable, and JetStream is more limited than most Kafkas on number of streams. ↩
-
Storage cost for OLTP stores is typically upwards of $0.25/GiB, vs $0.05/GiB with S2. Compute and I/O costs will also be significantly higher — OLTP databases are geared at flexible transactional workloads, rather than purely append-only writes and sequential reads. ↩
-
OLAP stores require accumulating large write batches for cost efficiency of storage and query-time compute, and this translates into high write latencies. In fact, streams are often used as a buffer in front of an OLAP destination. ↩
-
While this resembles retrieval-augmented generation (RAG), it is fundamentally different: instead of augmenting with external knowledge, we are selectively retrieving the agent's own memories to reconstruct relevant context. ↩
-
MemGPT makes the connection to an operating system's virtual memory model, and I think there is also a fair analog to log-structured merge-tree construction. ↩
-
Straightforward to DIY, but we are thinking along the lines of a native
cloneAPI so we can make it faster and cheaper. ↩