Postgres plays a crucial role in the modern OLTP landscape. However, there are lots of good reasons to synchronize PG rows elsewhere — it is common to need the same data in an OLAP store, or derive state like caches and indexes.
Avoiding delays by design
Traditional data integration approaches have relied on batch processing, where data pipelines periodically extract full or partial datasets and load them into downstream processors.
The apparent simplicity is a mirage:
- Bloated full dumps introduce significant overheads and latency as updates are only reflected with each batch cycle which may only be feasible hourly, daily, or even weekly.
- Periodic incremental loads with timestamp-based queries are certain to go wrong over time, as clocks are never perfectly synchronized.
- Real-time use cases that require reacting to specific state changes as they happen are not feasible, and this leads to managing application-level triggers.
Change Data Capture (CDC) flips this model by capturing changes as they occur in the database.
The idea is to leverage the database’s write-ahead logging, and produce a stream of logical changes. Instead of moving entire datasets, CDC streams deltas — insert, update, and delete operations — in real-time.
This is exactly what you need in a modern event-driven architecture.
Batch Processing │ Event-Driven
═════════════════════════════════════│════════════════════════════════════════════════
Order Created │ Order Created ───▶ Stream ──▶ Services
Payment Processed │ Payment Processed ─▶ Stream ──▶ Services
Inventory Updated │ Inventory Updated ─▶ Stream ──▶ Services
User Registered │ User Registered ──▶ Stream ──▶ Services
Status Changed │ Status Changed ──▶ Stream ──▶ Services
│ │ │
│ (accumulate...) │ ▼
▼ │ ┌─────────────┐
┌─────────────┐ │ │ Real-time │
│ Process all │ │ └─────────────┘
│ at once │ │
└─────────────┘ │
│
Flow: │ Flow:
[──wait──][process][──wait──] │ [→][→][→][→][→][→][→][→]
│
Resources: │ Resources:
Idle ──── Spike ──── Idle │ ~~~~~~ Steady ~~~~~~Sequin just makes sense
In the current ecosystem of CDC tools, Debezium is quite established. However, it comes with significant operational overhead due to being built around Kafka Connect, a heavy-weight framework that has not kept up with the cloud-native times.
You may also know about Postgres triggers or LISTEN/NOTIFY. Both seem alluring, but come with gotchas:
- Postgres triggers can execute code in response to database changes, but they are constrained to
PL/pgSQLand run synchronously within the transaction, impacting database performance. - Similarly,
LISTEN/NOTIFYprovides a lightweight pub/sub mechanism, but offers only at-most-once delivery — if your consumer is offline or fails, notifications are lost forever, and there is no way to replay missed events.
Sequin has been developed as a modern, focused system that addresses these pain points. It eliminates the Kafka dependency and gives you the freedom to choose your ideal sink. It can run as a single Docker container that connects directly to a Postgres database, and stream changes to many destinations like SQS, HTTP endpoints, Redis – yes Kafka too – and now S2!
What makes Sequin particularly compelling is its focus on operational use cases - the scenarios where you need to trigger workflows, invalidate caches, send notifications, or keep services synchronized based on database changes. Unlike ETL tools like Fivetran or Airbyte that excel at analytical workloads but operate in batch intervals, Sequin delivers real-time streaming.
Making streams first-class
We have been building S2 as a true counterpart to object storage for fast data streams. S2 gives you streams on tap behind a very simple API, with no clusters to deal with whatsoever.
Each stream is totally ordered, and elastic to very high throughputs – 10-100x higher than most cloud streaming systems. So if you wanted to capture the precise order of all operations in a write-heavy table on a single stream, S2 can keep up!
On the other end of the spectrum from a high-throughput firehose, you can get as granular as you need to: streams are a first-class, unlimited resource in S2. We take responsibility for ensuring a high quality of service, such that a variety of streaming workloads can operate seamlessly.
Elastic throughput, bottomless storage, unlimited streams, and a serverless model where you only pay for usage – all make S2 an especially good fit for CDC from serverless Postgres databases, like Supabase, Neon, and Nile.
Trying it out
Let's look at how we can architect a simple and fast CDC pipeline from Postgres to S2 with Sequin.
Imagine you're managing an item inventory where you need to update prices and quantities, as new stock arrives or in response to changes in demand and supply. These updates need to be propagated to users in real-time, which can be a complex process as it may involve:
- Triggering notifications or alerts e.g. "Avocados are now $4.99!"
- Revalidating caches, as a product going out of stock may require invalidating various caches or updating search indexes, so users don’t end up trying to check out a product that is no longer available.
- Internal updates to adjust profit margins and pricing, which may be owned by other microservices.
You can also follow along the same example via Sequin's S2 quickstart.
Consider the following schema for our inventory:
create table products(
id serial primary key,
name varchar(100),
price decimal(10, 2),
inserted_at timestamp default now(),
updated_at timestamp default now()
);We will start by creating an S2 basin and generating an access token.
To create a basin, navigate to the basins tab in the S2 dashboard and click on Create Basin:
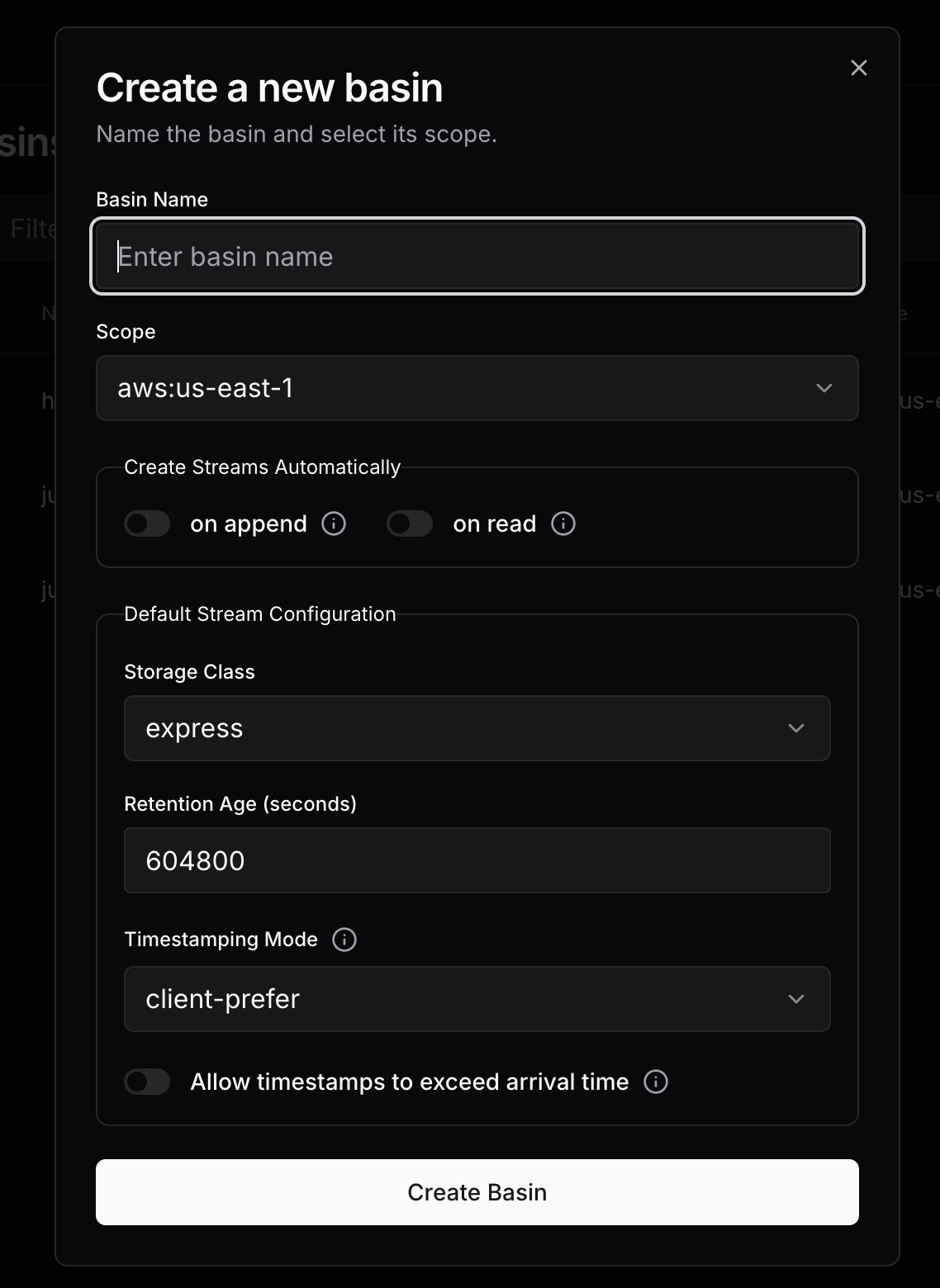
Enable the on append option in the Create Streams Automatically section so that you don’t have to explicitly create streams.
Now, create an access token by navigating to the Access tokens tab, and then clicking on Issue.
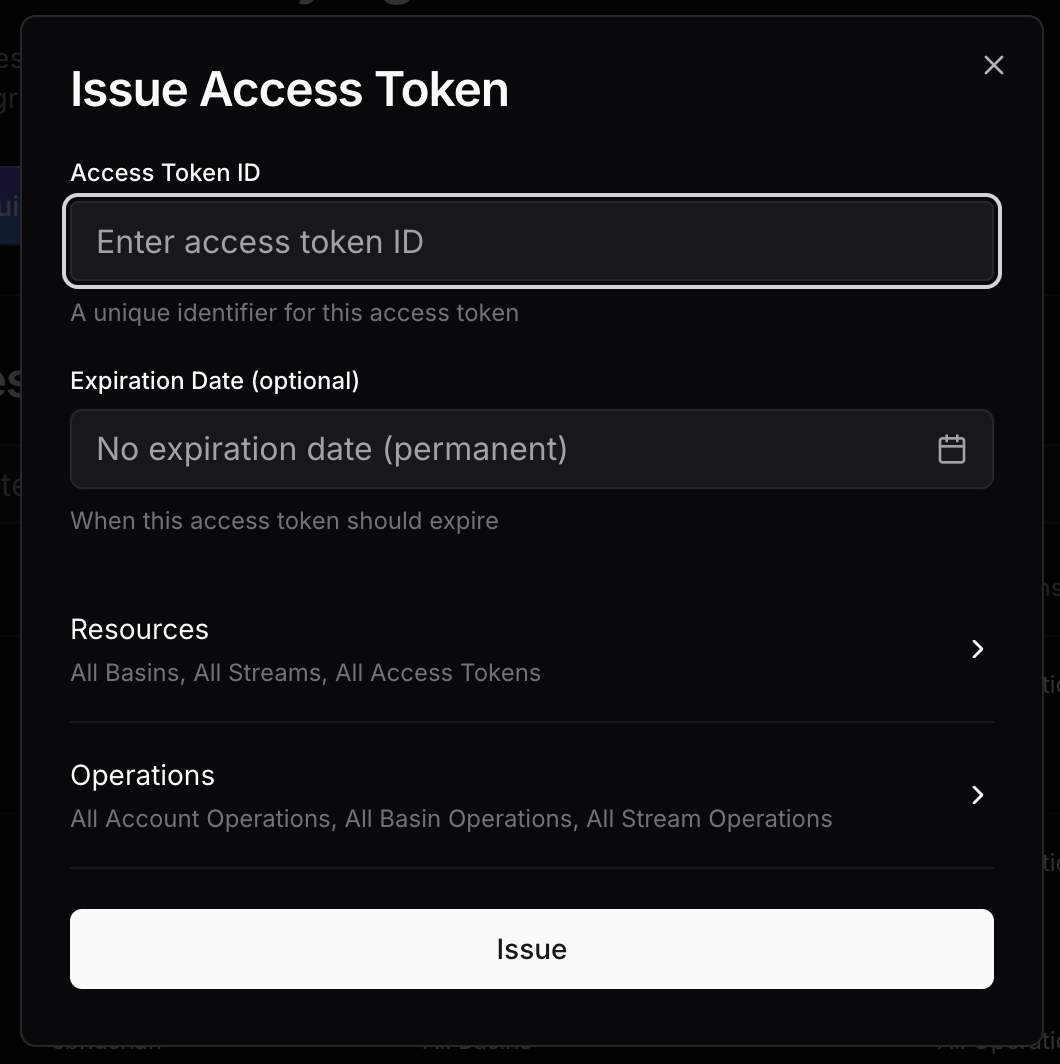
Use a fine-grained access token scoped to the exact basin or the stream you want to use as a sink for CDC, and restrict the allowed operations to Append only, or Append and CreateStream if you enabled automatic creation of streams.
Next, follow the Sequin Postgres guide on how to connect your database to Sequin. After connecting your Sequin dashboard, wait for the connection to be healthy, and then add a new sink by choosing S2.

Fill out the S2 configuration and click on Create Sink. Sequin will start sending CDC events to our S2 stream!
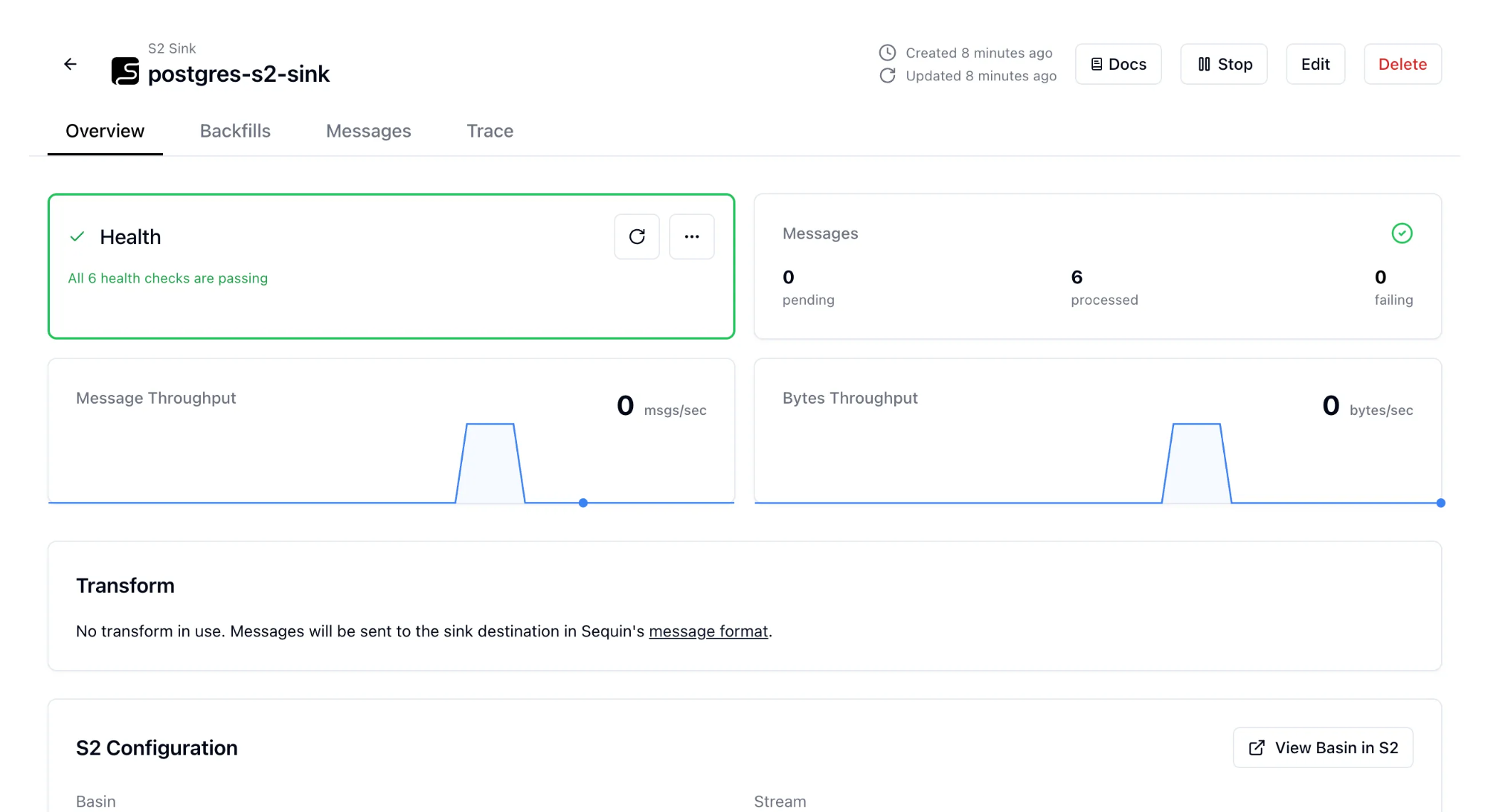
We can verify this by tailing our S2 stream to see updates sent to the products stream in the Sequin message format:
$ s2 read s2://sequin-quickstart/products
⦿ 3500 bytes (6 records in range 6..=11)
{"record":{"id":1,"inserted_at":"2025-06-11T01:19:22.402358","name":"Avocados (3 pack)","price":"5.99","updated_at":"2025-06-11T01:19:22.402358"},"metadata":{"consumer":{"id":"282713d8-76c4-42db-8e16-3e0df04cc5f6","name":"sequin-playground-s2-sink","annotations":null},"table_name":"products","commit_timestamp":"2025-06-17T19:19:51.955551Z","commit_lsn":null,"commit_idx":null,"transaction_annotations":null,"table_schema":"public","idempotency_key":"ODQ5NWNhMzEtYTM0MC00MDI5LThjODItMTcxYmRjMmY4YjI2OjE=","database_name":"sequin-playground"},"action":"read","changes":null}
{"record":{"id":2,"inserted_at":"2025-06-11T01:19:22.402358","name":"Flank Steak (1 lb)","price":"8.99","updated_at":"2025-06-11T01:19:22.402358"},"metadata":{"consumer":{"id":"282713d8-76c4-42db-8e16-3e0df04cc5f6","name":"sequin-playground-s2-sink","annotations":null},"table_name":"products","commit_timestamp":"2025-06-17T19:19:51.955968Z","commit_lsn":null,"commit_idx":null,"transaction_annotations":null,"table_schema":"public","idempotency_key":"ODQ5NWNhMzEtYTM0MC00MDI5LThjODItMTcxYmRjMmY4YjI2OjI=","database_name":"sequin-playground"},"action":"read","changes":null}
...Your applications can now easily consume these changes using an S2 SDK or its REST API.
It is worth highlighting that Sequin is not a dumb pipe – it also allows you to easily filter, transform, and route events!
Postgres Tables S2 Streams
┌─────────┐ ┌──────┐
│ users │──▶│ │─── user_auth_events
└─────────┘ │ │─── user_profile_updates
│ │
┌─────────┐ │SEQUIN│
│products │──▶│ │─── inventory_updates
└─────────┘ │ │─── price_alerts
│ │─── category_updates
┌─────────┐ │ │
│ orders │──▶│ │─── payment_notifications
└─────────┘ │ │─── order_processing
└──────┘Your CDC pipeline awaits
Modern applications are expected to be reactive. CDC with the right tools makes change propagation from databases a fundamental building block, rather than an advanced capability reserved for companies with large infrastructure teams.
Now you can combine Sequin's simplified Postgres CDC approach with S2's serverless streaming experience, and ship real-time features faster.
Join us on Discord.