Multi-player, serverless, durable terminals
S2 provides a serverless stream, or log primitive, backed by object storage. You can think of it as the core of Kafka, just... liberated from all the infra associated with it.
We've been enjoying plugging S2 into anywhere streams appear, just to see what happens. Which leads us to:
What if we implemented a terminal on S2?
Terminals are basically streams, right?
Suppose I want a shell on a remote system. I'd probably run sshd on that system – sshd would serve the role of pseudoterminal (or PTY), by interacting with a local shell process – and sshd would then broker access to this shell for any clients that connect to the system, via the SSH protocol.
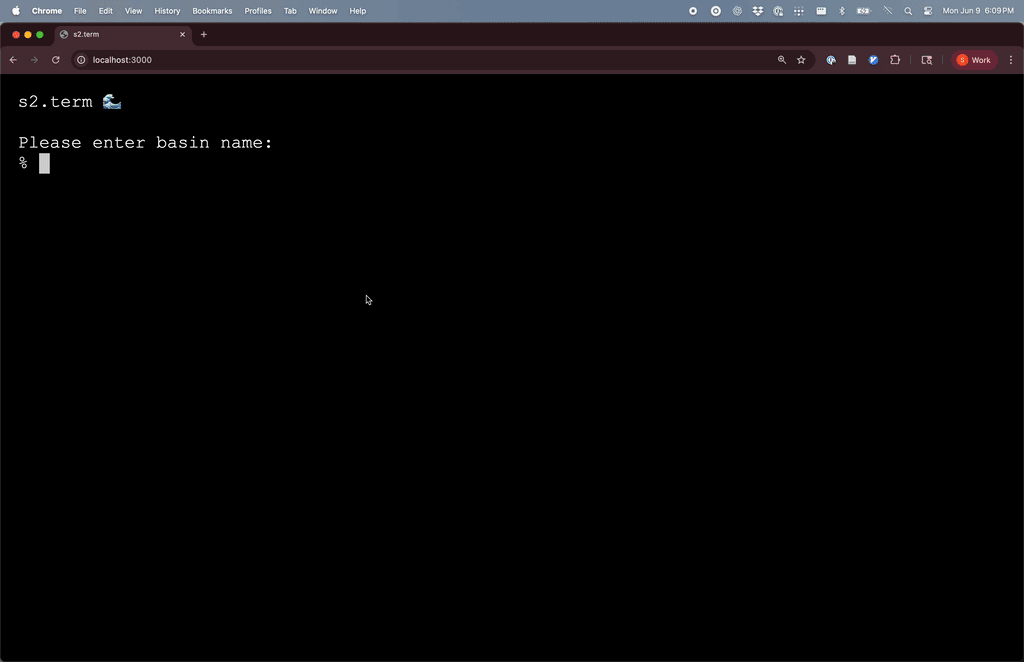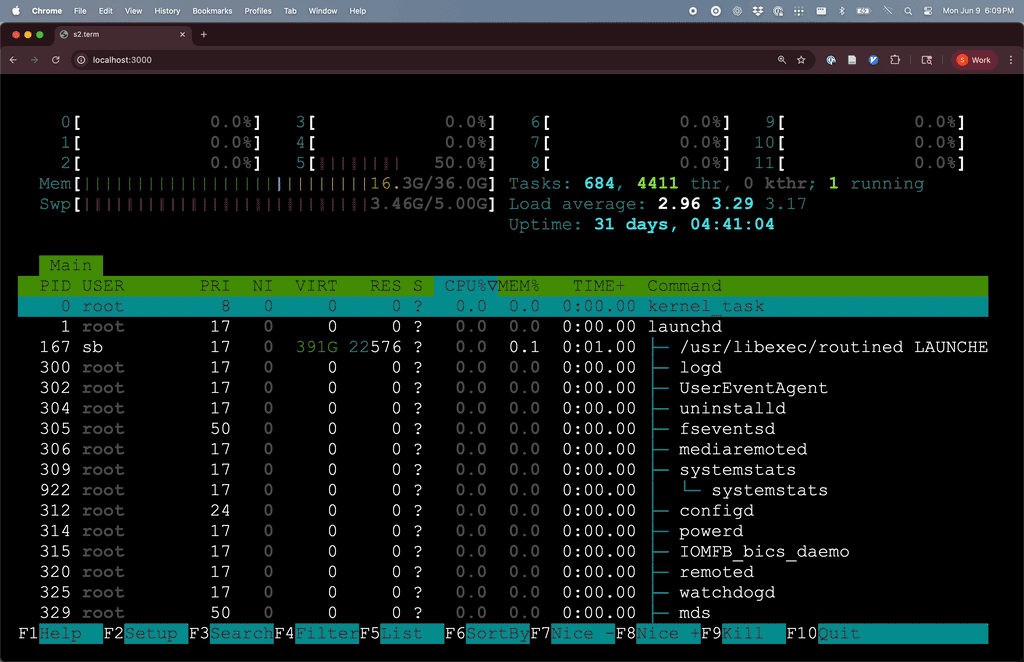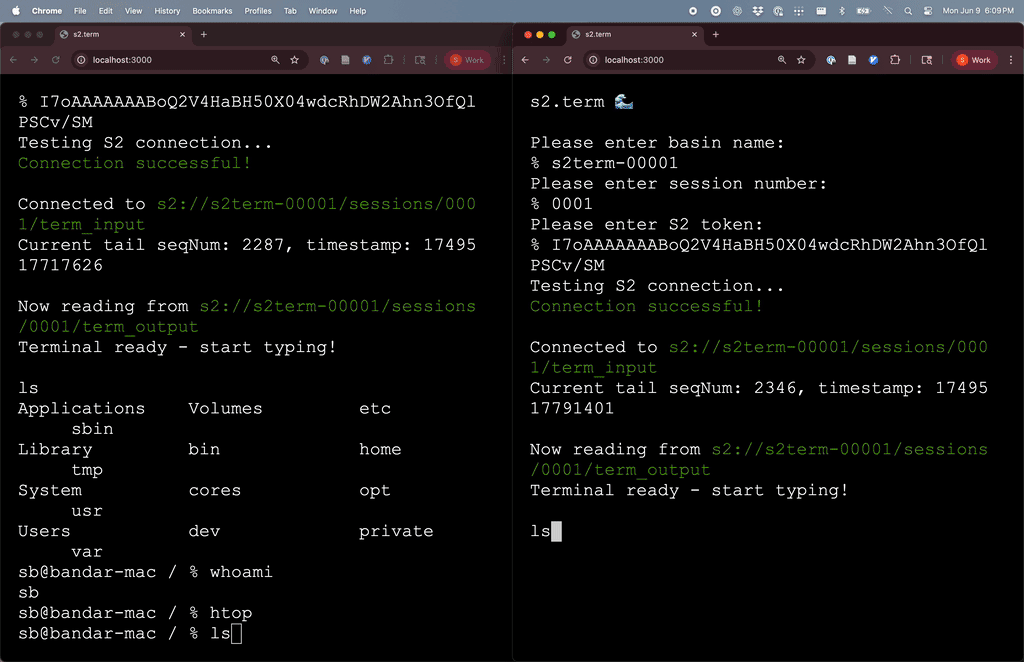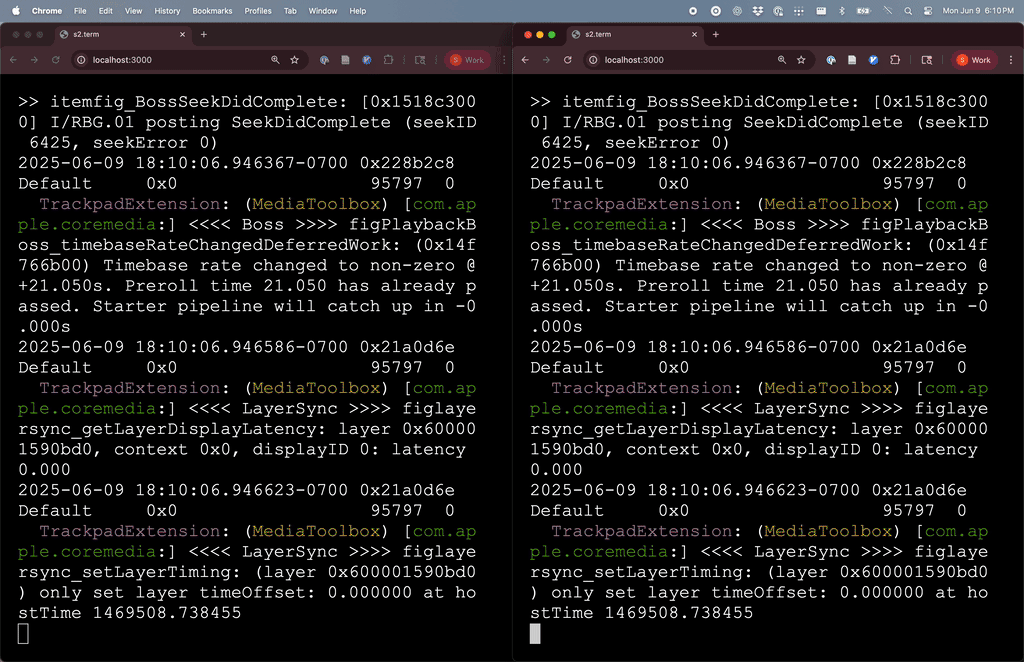
So what if we replaced sshd with our own pseudoterminal, which instead of running as a server daemon communicates entirely through S2?
As it turns out, this is pretty easy to hack together! Shoutout to Claude for vibing the frontend in particular.
How does it work?
For a pseudo-terminal, we just need to read inputs (keystrokes, window resize events, mouse clicks) from an S2 stream, delegate them to a shell process, and then stream the terminal output back onto another S2 stream.
In this demo, the client is simply a webpage with xterm.js, and we can coordinate with S2 streams directly from the browser over HTTP. I used the S2 TypeScript SDK, but plain old REST works too.
The PTY process is a small Rust binary, which interacts with S2 via (you guessed it) the Rust SDK, and makes use of the portable_pty crate.
See a video of the demo setup in action here. Or check out the repo and try it yourself.
This has to be incredibly slow, right?
Interactive latency in a setup like this is for sure higher than connecting directly to my server over SSH.
In my case, I'm running the PTY process on a VM in us-east-1, and I want to get a shell on it from my home in California, where I am running the frontend locally.
With an Express storage-class stream on S2, p50 end-to-end latencies are around 25-30ms, with p99 < 50ms – but this is for a client in the same region as S2. While we are in preview, S2 is only in AWS's us-east-1 – and since I live in California, I have to pay a pretty significant "speed-of-light tax" to get bytes to and from Northern Virginia. At least the weather's nice!
Let's consider what has to happen on every interaction (e.g. a single keystroke) for this S2 terminal:
- Frontend appends the keystroke to an S2 stream (California ->
us-east-1+ time to make a write durable within a region). - The Rust PTY, on the VM, needs to read the (now completely durable) keystroke (same region, on an already open streaming read session).
- The PTY sends the keystroke to its follower process (a shell); that process may simply be echoing, e.g. if I'm just typing in a command prompt.
- The PTY writes any output from the shell to an S2 stream (the VM running this PTY is in the same region as S2, so this is just time to make a write durable within a region).
- The output needs to be read, by the frontend, from an S2 stream (
us-east-1-> California, on an already open streaming read session).
Here's what it looks like put together:
 |
|---|
Flow of the s2.term setup |
We can approximate the latency for steps 1 and 4 at the same time by running the S2 CLI's ping function, from my laptop in California, and looking at the end-to-end latency.
This ends up being around 124ms, p50.
 |
|---|
Home (in California) to S2 in us-east-1 ping test. |
And similarly, we can approximate latency for steps 2 and 3 by running that command from an EC2 VM in us-east-1.
This is around 31ms, p50:
 |
|---|
| Intra-region ping test. |
This means each keystroke I make on the terminal frontend takes about 155 milliseconds to be reflected back to me, given my distance. This latency is dominated by the input and output stream appends. If I were just using ssh, the latency would be closer to 70 or 80ms.
... but 155ms is actually not terrible for a terminal? Definitely not the snappiest I've ever used, but probably not the worst either.
Why do this?
The honest answer is: I was bored last Friday and thought it would be fun to try out. And it was!
But there are some cool properties which emerge when you do this. For instance:
... the terminal is automatically multi-player
It's surprisingly good for pair programming.1 You can have multiple people controlling a terminal without having to spin up a server, or grant SSH access (e.g. if sharing via tmux).
You also get fine-grained access-controls at a per-stream (or per-stream prefix) level. So you could easily choose to only grant read-only access (i.e., terminal viewers), or read-write but limit certain operations like trim.
Plus, you could even make use of concurrency primitives for further safety (e.g., ensure all terminal users are fully caught-up with the tail of the terminal before their keystroke can be appended).
These types of things become easy when your terminal is essentially a shared write-ahead log.
... all I/O is automatically saved
Every S2 write has to be regionally durable in object storage before it can be delivered to readers, and you can control how long you want to retain stream history for (or just trim it explicitly).
This has some neat implications – for instance, you can share a "replay" (Asciinema-style) of a pair programming session for someone who couldn't make it when it was going on live.
Or, maybe you want to broadcast content from a TUI dashboard running on a server, and allow people to scrub around and see values from earlier. Records are indexed by timestamp in addition to their sequence number, so you can easily hop around to points of interest in a terminal session, or replay at different speeds, like having a "rewind" button on your terminal. See a demo video of that here.
... no servers to configure
With sshd, you need to make sure users can connect to the daemon – meaning you might have to forward ports in a gateway, or otherwise deal with NAT traversal. With S2 serving as the streaming medium, both the client and the server just need to be able to connect to the S2 API (which can be done via REST, or one of our SDKs).
What would it cost?
It really depends on what you are doing in your terminal!
S2 is priced as a serverless commodity, along dimensions that will be familiar to anyone who uses object storage, making it easy to do some math based on expected usage patterns.
As a somewhat maximalist example, I wanted to see what it would cost if I turned btop – which is a dynamic TUI dashboard for monitoring system activity – running on a computer of mine into a shared dashboard by broadcasting that process over S2 (e.g., as I did in this video).
btopproduces around 800KiB of terminal output per minute- About 1.1GiB of data written in a day.
- 0.066 for
Expresswrites (as I opted for the lower-latency storage class) - 0.044 for storage for 24 hours
- ~= 11 cents / day
- 0.066 for
- Reads require us to estimate usage (how many people will be connected)
- 3 users tailing continuously, all day long
- $0.08 (per GiB over public internet) _ 1.1GiB _ 3 users
- ~= 26 cents / day
- 3 users tailing continuously, all day long
- Per-op costs
- Total on the order of <1 cent per day.
- About 1.1GiB of data written in a day.
So around 38 cents per day to share my btop and a day's worth of history with the rest of the office!
Footnotes
-
Though, when using TUIs that resize dynamically based on the cols/rows of the client's window, you have the same problem as with
tmux, where everyone needs to agree on a single virtual window size. ↩